

AI's Long Tail Problem Requires Synthetic Data
If edge cases are by definition hard to find, we need computer-generated data to fill the gaps

AI has a long-tail problem. Let’s take the completely-unrelated-to-my-job example autonomous cars.
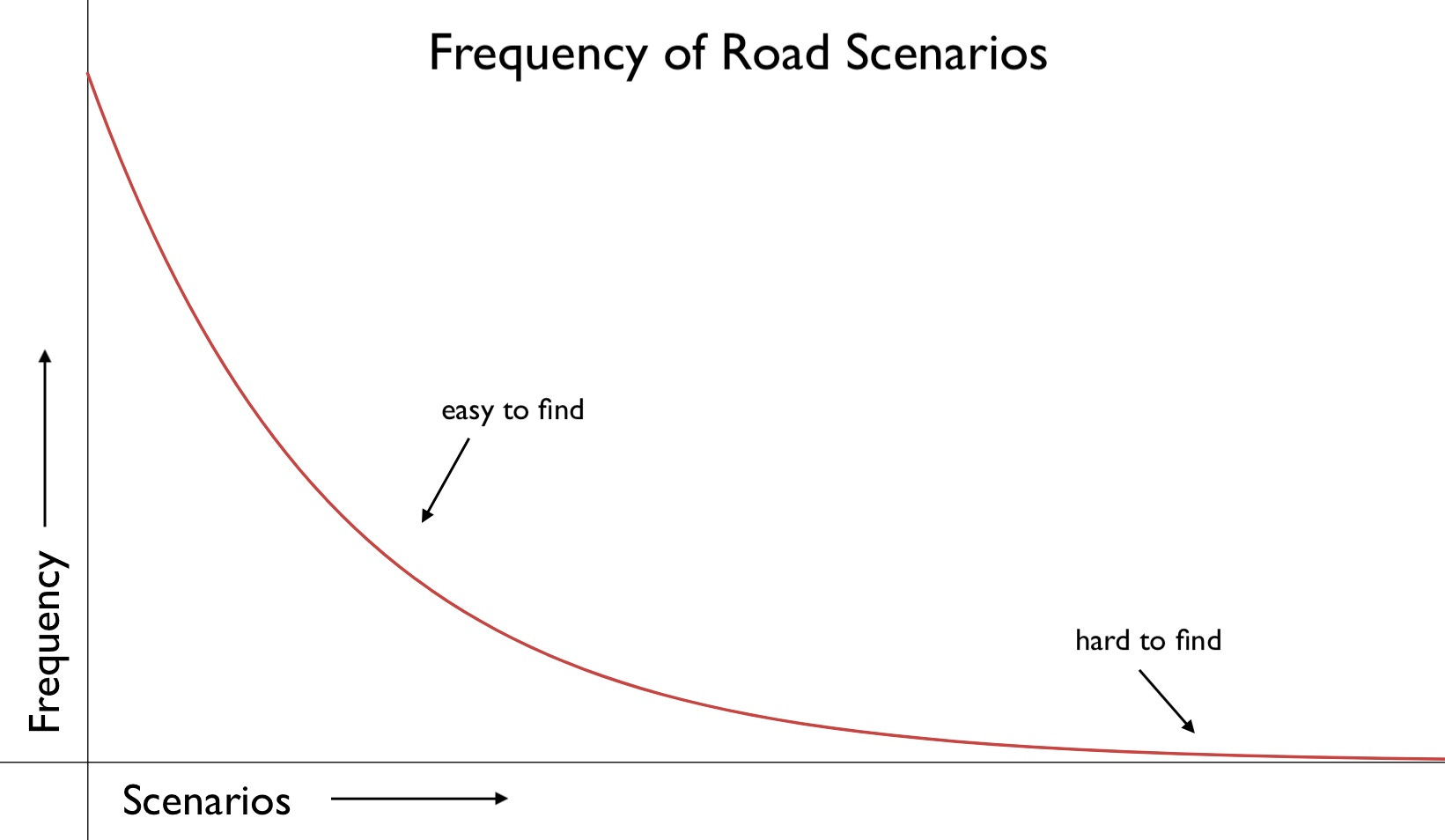
Imagine scenarios are sorted by rarity on the x-axis. At x=1, we might have a typical highway driving scenario. At x = a big number, we might have something like… a lamppost falling down in front of the car during a rainstorm with debris blocking part of the camera.
This is a problem. Rare scenarios don’t happen often enough to provide sufficient data to train machine learning models, but because of the scale of a self-driving fleet, they are encountered every single day.
This problem is hard to solve with traditional data collection where self-driving car companies send out huge fleets on the road. Such fleets are doomed to sample from the long-tail distribution. Each car at each timestep records a scenario with the probability that it actually occurs. So to collect enough data for an edge case might take weeks - and then you have to sift through all the collected data to find it, and then you have to label it by humans. We’re talking months of turnaround time.
Synthetic data changes the game because it’s programmable. With synthetic data, you don’t have to sample from the distribution. You can pick x = whatever you want and generate as much data as you’d like. Construction scenarios? Sure, no problem. Lens flares blocking pedestrians crossing in front of the car? Yep, we can make a thousand scenes of that. Generating edge cases is just as easy as generating frequent ones. Synthetic data is magical, and it works. The revolution of machines training machines begins today.